什么是rdd
RDD,全称为 Resilient Distributed Datasets,弹性分部署数据集,是为了对用户操作的简化,以面向对象的方式提供了RDD很多方法,rdd是懒执行的,分为转换和行动两部分
rdd特性
- 不可变,所有rdd操作会产生一个新的rdd
- 可分区,通过将数据进行分区保存
- 弹性
存储的弹性: 内存与磁盘的自动切换
容错的弹性: 数据丢失可以自动恢复
计算的弹性: 计算出错重试机制
分片的弹性: 根据需要重新分片
spark都做了什么:
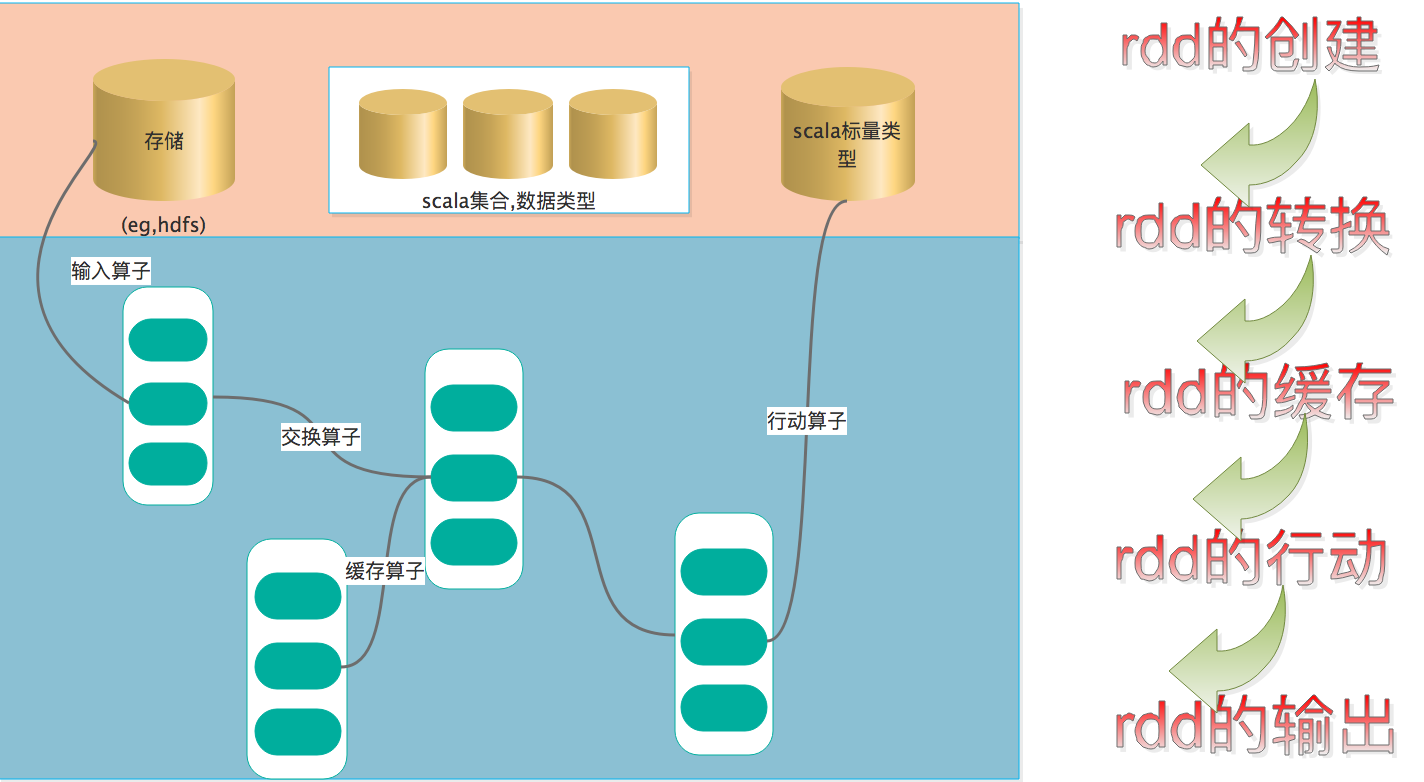
rdd创建
rdd创建方式分为3种:
从集合中创建
在Driver(驱动程序)中一个已经存在的集合(数组)上创建,SparkContext对象代表到Spark集群的连接,可以用来创建RDD、广播变量和累加器。可以复制集合的对象创建一个支持并行操作的分布式数据集(ParallelCollectionRDD)。一旦该RDD创建完成,分布数据集可以支持并行操作,比如在该集合上调用Reduce将数组的元素相加。
1 | scala> sc.makeRDD(0 to 10) |